
NVIDIA researchers just unveiled PersonaPlex 7B-v1, a groundbreaking 7 billion parameter model that powers natural, full duplex speech to speech conversations. Unlike traditional voice assistants, it handles interruptions, overlaps, and backchannels seamlessly think fluid chats where both sides talk over each other naturally, without awkward pauses.
This open source gem (code under MIT license, weights via NVIDIA Open Model License) targets precise persona control, letting agents adopt specific voices, roles, and styles on the fly. Released on January 17, 2026, it’s designed for real world apps like customer service bots or virtual companions that feel truly human.
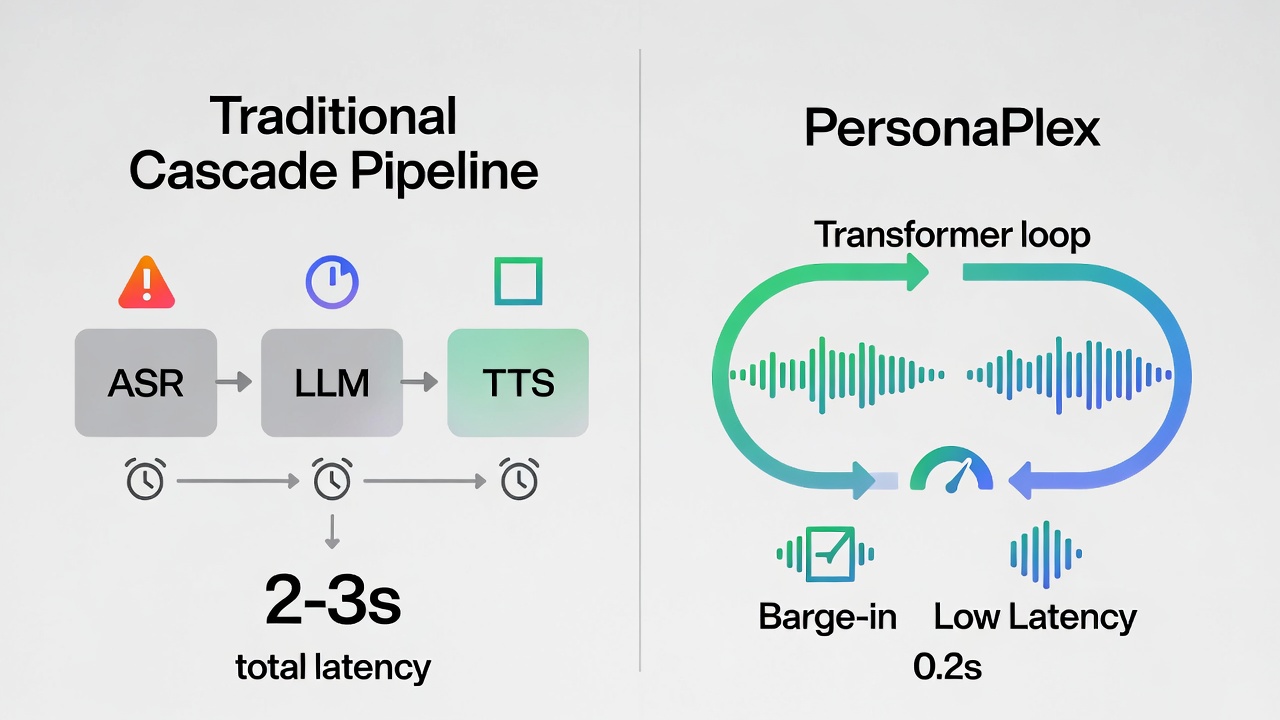
The Shift to Duplex Chat
Conventional voice systems chain three steps: speech to text (ASR), text response from a language model, and text to speech (TTS). Each adds latency, often 1-3 seconds, and fails at overlaps or interruptions, making talks feel robotic.
PersonaPlex flips this with one Transformer model handling everything in real time. It processes continuous audio via a neural codec, predicting text and audio tokens together. One stream tracks your speech; another generates the agent’s reply. Shared model states let it listen while talking, adapting instantly to interruptions. Inspired by Kyutai’s Moshi framework, this dual stream setup shines in dense dialogues, mimicking human rhythms like “uh-huh” backchannels or quick turn taking.
Adding depth: Similar to advancements in models like Google’s AudioPaLM or Meta’s Voicebox, PersonaPlex reduces end to end latency to under 250ms faster than human reaction times in many scenarios (per psycholinguistic studies on conversation dynamics).
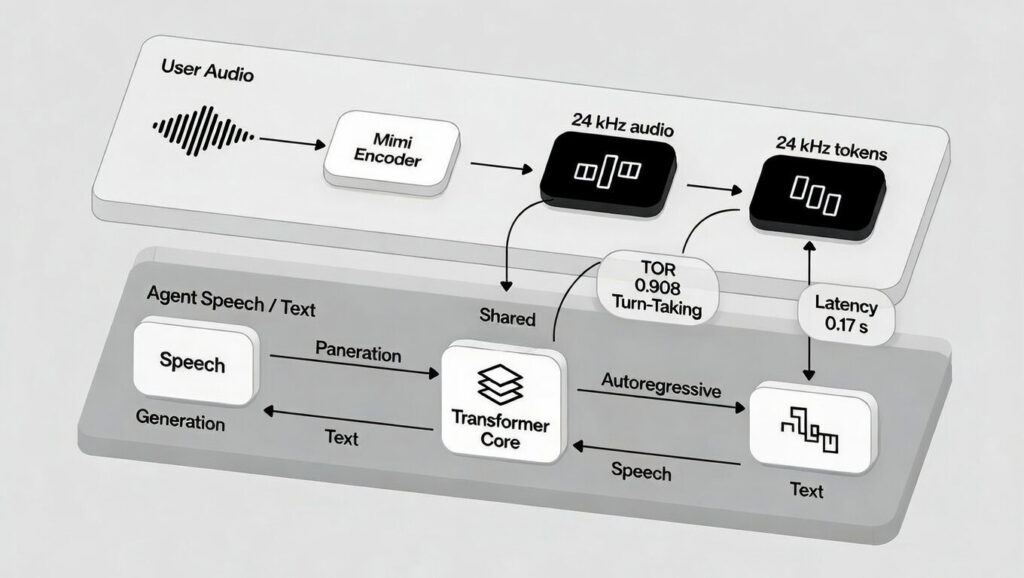
Hybrid Prompts for Voice AI
PersonaPlex defines an agent’s identity with two prompts: a voice prompt (audio tokens capturing timbre, style, prosody, like a warm teacher or crisp executive) and a text prompt (role, background, scenario details). A system prompt adds up to 200 tokens for name, business info, or rules.
This combo ensures linguistic smarts match acoustic flair. Pre built embeddings like NATF (natural female) or NATM (natural male) families make setup plug-and-play. For example, prompt it as a Mars mission engineer, and it delivers technical fixes with an urgent tone even on untrained scenarios, thanks to Helium’s backbone for out-of-distribution reasoning.
Extra insight: NVIDIA notes this mirrors multimodal prompting in LLMs like GPT 4o, but audio first. Early tests show 65% speaker similarity (via WavLM embeddings), outperforming rivals in voice fidelity.
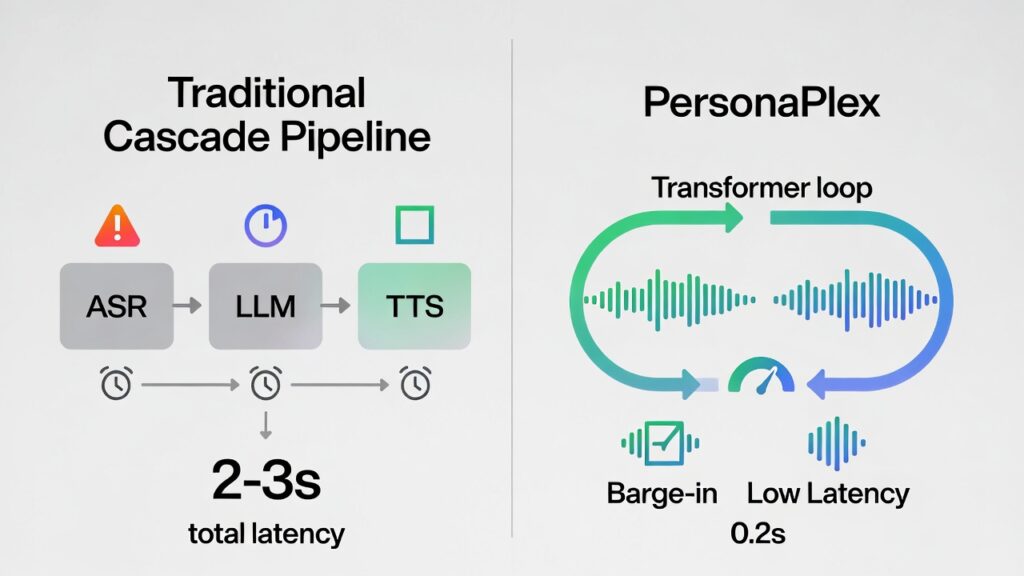
Helium-Powered Architecture
At its core, PersonaPlex 7B uses Moshi’s architecture with Helium as the LLM backbone for deep semantics. A Mimi encoder (ConvNet + Transformer) turns 24kHz waveforms into tokens. Multi channel Transformers process user audio, agent text, and output audio. A matching decoder generates speech.
Helium’s generalization stands out: In a “space emergency” demo (reactor failure on Mars), it reasons coherently with emotional prosody beyond training data. This 24kHz fidelity rivals studio quality, supporting diverse accents and emotions.
Training: Real Talks Meet Synthetic Scenarios
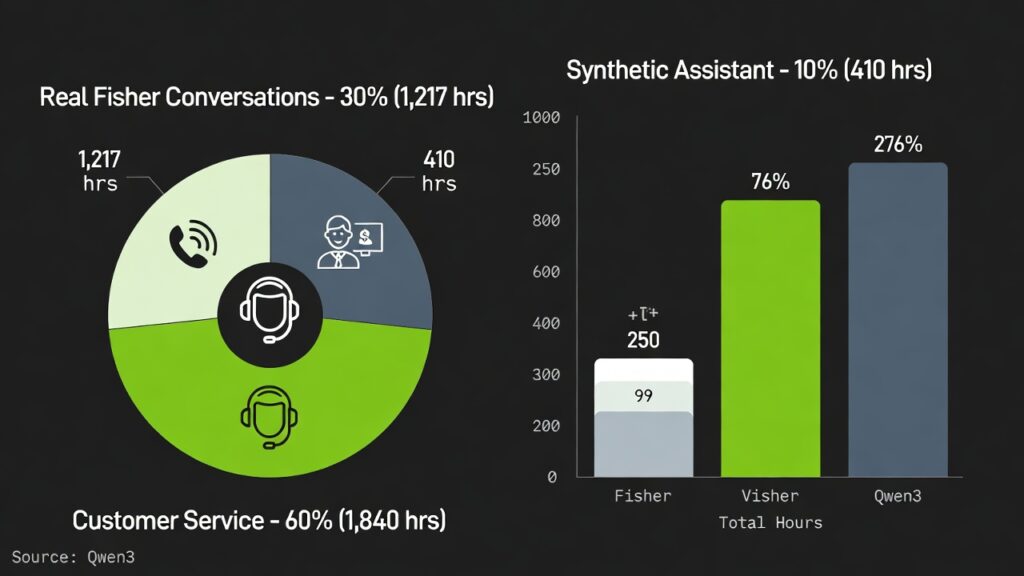
Training blends 7,303 real Fisher English calls (1,217 hours) for natural flow backchannels, pauses, disfluencies annotated via GPT-OSS-120B prompts from hints to full bios. Synthetic data adds 39,322 assistant chats (410 hours) and 105,410 customer service ones (1,840 hours), scripted by Qwen3-32B/GPT-OSS-120B and voiced via Chatterbox TTS.
This split teaches naturalness (from Fisher) separately from role adherence (synthetic), boosting flexibility. NVIDIA’s approach echoes scaled datasets in Llama 3, yielding robust zero shot performance.
Benchmarks: Crushing Duplex Challenges
Tested on FullDuplexBench (dynamics like turn-taking) and new ServiceDuplexBench (service tasks), PersonaPlex scores high: smooth turn-taking takeover rate (TOR) of 0.908 at 0.170s latency; interruptions at 0.950 TOR / 0.240s. GPT 4o judges praise response quality. It beats open/closed rivals in latency, adherence, and naturalness.
| Metric | PersonaPlex Score | Latency | Notes |
|---|---|---|---|
| Smooth Turn-Taking (TOR) | 0.908 | 0.170s | Handles pauses/backchannels |
| User Interruptions (TOR) | 0.950 | 0.240s | Sub-second adaptation |
| Speaker Similarity | 0.650 | N/A | WavLM embeddings |
Why PersonaPlex Matters
This model paves the way for lifelike AI agents in calls, therapy bots, or gaming NPCs. Download the weights and experiment—its open nature invites tinkers to build next-gen voice tech.
The Future of Talking AI
PersonaPlex 7B v1 isn’t just another model it’s a leap toward AI that converses like a human, interruptions and all. Developers can grab the open weights today and craft custom agents for customer support, education, or even sci-fi roleplay.
As voice tech evolves, expect integrations with AR glasses or smart homes, slashing latency barriers. NVIDIA’s blend of real and synthetic training sets a blueprint for scalable, persona-driven AI. Dive in, experiment, and watch conversations transform.
What natural language breakthrough are you most excited for next?
Want more deep dives on AI, tech, and cybersecurity? Do visit our other blog posts on the site – we regularly cover the latest in AI models, tools, and digital security in simple, easy-to-follow guides. Whether you’re into cutting‑edge language models, real‑world tech trends, or staying safe online, there’s something in our AI, Tech, and Cybersecurity sections for every curious mind.



